2025-12-15 01:15:50.330624: I external/local_xla/xla/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2025-12-15 01:15:50.379550: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-12-15 01:15:51.941159: I external/local_xla/xla/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
/opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages/keras/src/layers/reshaping/reshape.py:38: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(**kwargs)
2025-12-15 01:15:52.961884: E external/local_xla/xla/stream_executor/cuda/cuda_platform.cc:51] failed call to cuInit: INTERNAL: CUDA error: Failed call to cuInit: UNKNOWN ERROR (303)
2025-12-15 01:15:53.151103: W external/local_xla/xla/tsl/framework/cpu_allocator_impl.cc:84] Allocation of 188160000 exceeds 10% of free system memory.
AttributeError: 'list' object has no attribute 'shape'
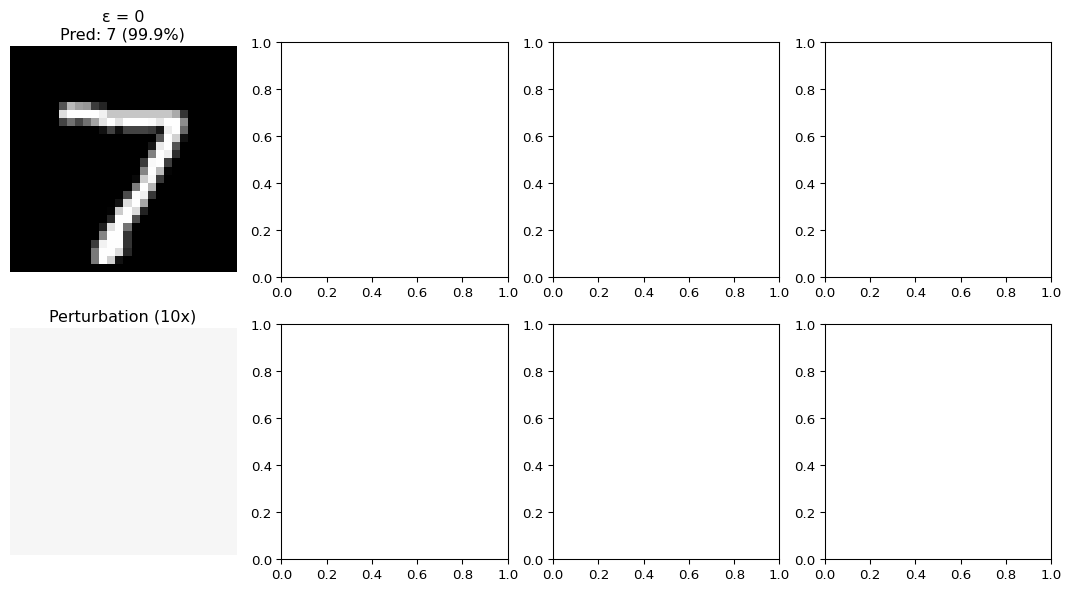
Figure 24.1: FGSM adversarial attack on MNIST
How FGSM Works
The Fast Gradient Sign Method computes:
\[x_{adv} = x + \epsilon \cdot \text{sign}(\nabla_x L(\theta, x, y))\]
where: - \(x\): original image - \(\epsilon\): perturbation magnitude - \(\nabla_x L\): gradient of loss with respect to input
Defense Strategies
Defense
Description
Effectiveness
Adversarial Training
Train on adversarial examples
High
Input Preprocessing
Denoise, quantize inputs
Medium
Model Distillation
Train smaller model on soft labels
Medium
Ensemble Methods
Combine multiple models
High
Edge ML Defense
For edge devices, input validation is often the most practical defense: - Check input ranges - Detect unusual patterns - Reject outliers
Related Sections in PDF Book
Section 6.3: Adversarial Attacks
Section 6.4: Defense Mechanisms
Exercise 6.2: Implement adversarial training
Source Code
---title: "Adversarial Attack Demo"subtitle: "LAB06: Edge Security"---## FGSM Attack VisualizationSee how small perturbations can fool neural networks.::: {.callout-warning}## Security AwarenessThis demonstration shows how adversarial attacks work. Understanding attacks is essential for building robust edge ML systems.:::```{python}#| label: fig-fgsm#| fig-cap: "FGSM adversarial attack on MNIST"import numpy as npimport matplotlib.pyplot as pltimport tensorflow as tf# Load a pre-trained model and sample(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()x_test = x_test.astype('float32') /255.0# Simple CNN for demonstrationmodel = tf.keras.Sequential([ tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)), tf.keras.layers.Conv2D(32, 3, activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(10, activation='softmax')])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')model.fit(x_train.reshape(-1, 28, 28, 1) /255.0, y_train, epochs=1, verbose=0)# Select a sample imagesample_idx =0original_image = x_test[sample_idx]true_label = y_test[sample_idx]# FGSM Attackdef fgsm_attack(model, image, label, epsilon): image_tensor = tf.convert_to_tensor(image.reshape(1, 28, 28, 1))with tf.GradientTape() as tape: tape.watch(image_tensor) prediction = model(image_tensor) loss = tf.keras.losses.sparse_categorical_crossentropy([label], prediction) gradient = tape.gradient(loss, image_tensor) perturbation = epsilon * tf.sign(gradient) adversarial = tf.clip_by_value(image_tensor + perturbation, 0, 1)return adversarial.numpy().reshape(28, 28), perturbation.numpy().reshape(28, 28)# Generate adversarial examples with different epsilon valuesepsilons = [0, 0.1, 0.2, 0.3]fig, axes = plt.subplots(2, 4, figsize=(14, 7))for i, eps inenumerate(epsilons):if eps ==0: adv_image = original_image perturbation = np.zeros_like(original_image)else: adv_image, perturbation = fgsm_attack(model, original_image, true_label, eps)# Get prediction pred = model.predict(adv_image.reshape(1, 28, 28, 1), verbose=0) pred_label = np.argmax(pred) confidence = pred[0][pred_label]# Plot adversarial image axes[0, i].imshow(adv_image, cmap='gray') axes[0, i].set_title(f'ε = {eps}\nPred: {pred_label} ({confidence:.1%})') axes[0, i].axis('off')# Plot perturbation (magnified for visibility) axes[1, i].imshow(perturbation *10+0.5, cmap='RdBu', vmin=0, vmax=1) axes[1, i].set_title(f'Perturbation (10x)') axes[1, i].axis('off')plt.suptitle(f'FGSM Attack on Digit "{true_label}"', fontsize=14)plt.tight_layout()plt.show()```## How FGSM WorksThe Fast Gradient Sign Method computes:$$x_{adv} = x + \epsilon \cdot \text{sign}(\nabla_x L(\theta, x, y))$$where:- $x$: original image- $\epsilon$: perturbation magnitude- $\nabla_x L$: gradient of loss with respect to input## Defense Strategies| Defense | Description | Effectiveness ||---------|-------------|---------------|| Adversarial Training | Train on adversarial examples | High || Input Preprocessing | Denoise, quantize inputs | Medium || Model Distillation | Train smaller model on soft labels | Medium || Ensemble Methods | Combine multiple models | High |::: {.callout-tip}## Edge ML DefenseFor edge devices, **input validation** is often the most practical defense:- Check input ranges- Detect unusual patterns- Reject outliers:::## Related Sections in PDF Book- Section 6.3: Adversarial Attacks- Section 6.4: Defense Mechanisms- Exercise 6.2: Implement adversarial training